
Исследование персонажа Seven из Deadlock
Рубрикатор
1. Выбор данных 2. Мотивация и ценность анализа 3. Типы визуализаций 4. Этапы работы 4.1. Сбор данных 4.2. Обработка данных 4.3. Стилизация 4.4. Визуализация 5. Вывод 6. Инструменты и источники данных
Выбор данных
Для проекта я выбрала данные по игре Deadlock. Готовых наборов данных для анализа нет, поскольку игра находится на этапе альфа-тестирования. Однако благодаря публичному API игры у меня была возможность работать с реальными игровыми данными.
Изучив документацию, я собрала два набора данных по персонажу Seven, за которого часто играю, с помощью Python скриптов:
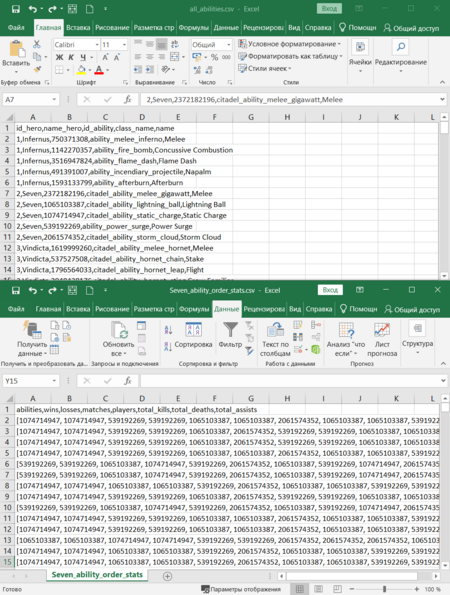
— Справочный датасет (all_abilities.csv), сопоставляющий идентификаторы способностей всех персонажей с их названиями.
— Основной датасет (Seven_ability_order_stats.csv), содержащий последовательности прокачки способностей (билды) для Seven в виде ID навыков, каждый из которых сопровождается матчевой статистикой (например, количество игр, процент побед).
Все данные представлены в табличном формате CSV и обработаны с использованием библиотеки Pandas для последующего анализа.»
Мотивация и ценность анализа

Персонаж Seven является одним из моих любимых героев в Deadlock, и в процессе игры возник ключевой вопрос: насколько сильно порядок прокачки способностей определяет успешность матча? Анализ именно этой последовательности, в отличие от сырой статистики побед/поражений, позволяет раскрыть не просто итог игры, а стратегическую причину успеха — цепочку решений, которые игрок принимает по ходу матча.
Особый интерес представляет также факт, что игра находится в альфе, а значит: — мета ещё не устоялась; — игроки экспериментируют с билдами; — оптимальные стратегии не всегда совпадают с самыми популярными.
Это делает анализ особенно ценным, так как работа с реальными игровыми данными позволяет: — выявить оптимальные паттерны прокачки, статистически ведущие к высокой эффективности (винрейт, KDA); — обнаружить скрытые зависимости: например, как выбор первой способности или комбинация переходов между умениями влияет на итог матча; — проанализировать мета-тенденции: какие сборки популярны у сообщества и почему — даже если они не самые эффективные; — сформулировать практические рекомендации для игроков, выбирающих данного персонажа.
Типы визуализаций
Набор графиков я выстраивала по принципу от общего к частному (популярность → эффективность переходов → глубинные зависимости → сравнение профилей) и выбирала наиболее подходящий и наглядный тип визуализации для ответа на конкретный вопрос.
Тип визуализации для каждого этапа выбирался исходя из конкретного вопроса:
— Горизонтальные столбчатые и круговая диаграммы — для сравнения общей популярности путей прокачки и анализа выбора первой способности. — Сгруппированные столбчатые диаграммы с аннотацией — для наглядного сравнения ключевых метрик (число матчей, винрейт, KDA) в разрезе переходов между соседними способностями. — Диаграммы рассеяния и тепловые карты — для выявления статистических зависимостей и корреляций между различными параметрами сборок. — Сгруппированные столбчатые диаграммы и радар-чарты — для многомерного сравнения профилей успешных и неуспешных сборок.
Этапы работы
Сбор данных
Работа с данными началась с изучения документации публичного API игры и написания базового скрипта на Python для тестовых запросов.
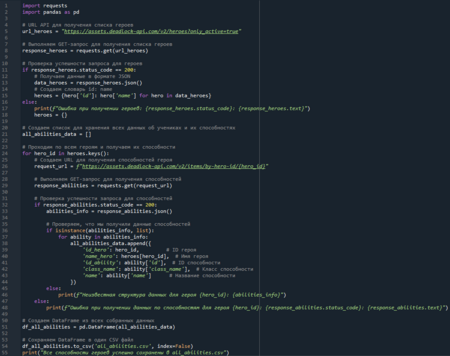
Первой практической задачей стало получение ID целевого персонажа — Seven. Поскольку этот ID был неизвестен, я нашла в API метод «Get Items By Hero Id» и с помощью ChatGPT доработала базовый скрипт (get_all_abilities_by_hero.py), чтобы он автоматически получал способности всех активных героев и сохранял их в единый CSV-файл.
Prompt: У меня есть Python-скрипт, который получает способности одного героя игры Deadlock по его ID. Мне нужно его доработать, чтобы он автоматически получил способности всех активных героев и сохранил их в один CSV-файл. Используй библиотеку pandas.
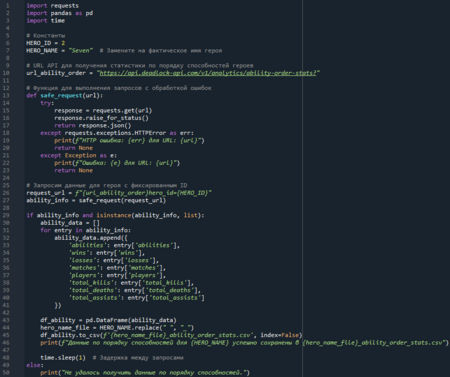
Узнав ID персонажа Seven, я приступила к сбору основного набора данных. Для этого с помощью ChatGPT был создан скрипт ability_order_stats.py, который, используя метод API Ability Order Stats, собирает статистику по порядку прокачки способностей для заданного героя и сохраняет её в структурированном виде.
Prompt: Мне нужно создать Python-скрипт для сбора статистики по порядку способностей конкретного героя из игры Deadlock через API. Для ID=2, имя персонажа «Seven». Метод API: https://api.deadlock-api.com/v1/analytics/ability-order-stats?. Обязательным параметр hero_id.
Обработка данных
После формирования сырых наборов данных я провела углубленный диалог с ChatGPT для планирования этапа визуального анализа. Мы обсуждали, как лучше предобработать данные и какие типы графиков наиболее наглядно ответят на поставленные вопросы о популярности, эффективности и скрытых зависимостях билдов. Результатом этого обсуждения стал скрипт preprocessing_data.py, который: загружает данные → предобрабатывает список способностей (список в массив + считает длину) → заменяет в Seven_ability_order_stats.сsv «ID» на названия способностей из «all_abilities.csv» → рассчитывает метрики винрейт, KDA и т.д → агрегирует данные для последующего построения графиков. На выходе получаем промежуточные результаты предобработки в отдельных CSV-файлах, однако не все в последующем использовались в построении графиков.
Prompt (первый): Есть данные по Deadlock: all_abilities — справочник ID и названий способностей всех героев; статистика по прокачке Seven — последовательности ID способностей (abilities) + метрики матчей (wins, losses, total_kills и др.) Хочу проанализировать и построить графики, чтобы: найти оптимальные порядки прокачки; увидеть, как первый выбор или комбинации скиллов влияют на игру; сравнить популярные и эффективные сборки; сделать практические выводы. Какие графики и подходы к анализу ты бы рекомендовал?
Стилизация

Чтобы графики визуально соответствовали предмету анализа, за основу стилизации был взят визуал персонажа Seven — сплав «стимпанка» и утилитарности. Цветовая палитра призвана отразить его холодную, технологичную атмосферу с яркими вспышками.
— Основной акцентный цвет: тыквенный (#FF4E18), отсылающий к энергетическим элементам его экипировки. — Фон и база: глубокий тёмно-синий (#0A0A14), создающий контраст и ощущение тактического интерфейса в духе вселенной Deadlock.
Визуальная стилизация была реализована на техническом уровне через выбор тёмной темы dark_background в Matplotlib и минималистичного шрифта, что напрямую отсылает к интерфейсной эстетике Seven. Ключевым элементом стала функция add_glow (), которая добавляет графическим элементам неоновое свечение, увеличивает толщину линий и задаёт обводкам акцентный цвет. Это буквально «заряжает» графики энергией, усиливая стилистическую связь с персонажем.
Визуализация
Визуализация данных о путях прокачки героя Seven
Первая визуализация — это демонстрация данных о путях прокачки героя Seven. Она позволяет исследовать топ-10 путей и распределение стартовых способностей, а также объясняет их успешность, отображая винрейт рядом с популярностью.
Для этого применяются ключевые статистические методы: — Ранжирование и частотный анализ для выявления топ-10 путей и самых частых первых способностей. — Расчёт относительных величин (винрейт, доли) для сравнения эффективности и структуры выбора. — Совмещение абсолютных и относительных показателей, чтобы одновременно оценить масштаб (количество матчей) и результативность (процент побед).
Что видно из графиков: 1. Static Charge — самая популярная стартовая способность (46.2% игроков). 2. Повтор одной способности дважды — самый частый выбор: Static Charge → Static Charge / Power Surge → Power Surge. 3. Популярность ≠ успех: самая используемая сборка показывает 53,5% винрейт, тогда как одна из менее популярных в подборке демонстрирует более высокую эффективность.
Визуализация эффективности переходов между способностями героя Seven
Вторая визуализация — сравнительно-оценочный график эффективности переходов между способностями героя Seven. Она позволяет исследовать взаимосвязь между популярностью, винрейт и игровой эффективностью (KDA) для топ-8 переходов, а также объясняет, какие комбинации являются самыми успешными и почему.
Для этого применяются следующие статистические методы: — Нормирование — приведение винрейт и KDA к единой шкале с количеством матчей для корректного визуального сравнения на одном графике. — Группированный анализ — прямое сравнение трёх ключевых метрик (популярность, результативность, эффективность) для каждого перехода через сгруппированные столбцы. — Сравнительная табличная сводка — компактное представление точных числовых значений в таблице, дополняющие визуальное восприятие. — Цветовое кодирование — использование градиентов оттенков серого в таблице для интуитивной оценки величины показателей (чем темнее, тем лучше). — Агрегация и ранжирование — выделение топ-8 самых частых переходов и расчёт их средних показателей (винрейт, KDA).
Что видно из графиков: — Static Charge → Static Charge — самый популярный переход. — Power Surge → Lightning Ball — самый успешный по винрейт. — Большинство игроков берут ту же способность дважды подряд. — Переходы с высокой популярностью имеют средний винрейт.
Визуализация взаимосвязей между длиной пути прокачки, винрейт и KDA героя Seven
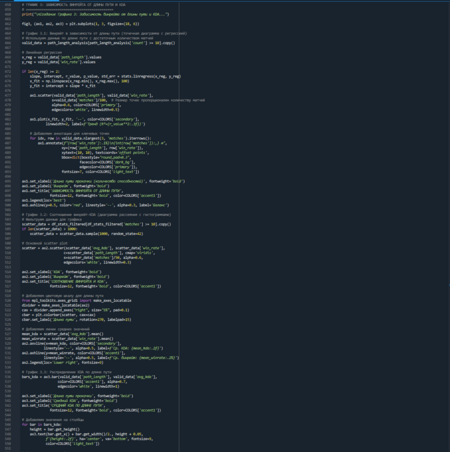
Третья визуализация — аналитические графики взаимосвязей между длиной пути прокачки, винрейт и KDA героя Seven. Она позволяет исследовать сложные зависимости между этими тремя ключевыми метриками и объясняет, как выбор определённой длины пути влияет на успешность игрока.
Для этого применяются следующие статистические методы: — Линейная регрессия — вычисление и визуализация тренда зависимости винрейт от длины пути с расчётом коэффициента детерминации (R²) для оценки силы связи. — Корреляционный анализ — исследование взаимосвязи между винрейт и KDA через диаграмму рассеяния с цветовым кодированием третьей переменной (длины пути). — Сравнение средних значений — использование горизонтальных и вертикальных линий на диаграмме рассеяния для сопоставления отдельных точек со средними по выборке. — Многомерная визуализация — одновременное отображение трёх переменных на одной диаграмме рассеяния через координаты точек (KDA и винрейт), их размер (количество матчей) и цвет (длина пути). — Агрегирование по группам — расчёт среднего KDA для каждого значения длины пути и представление результатов в виде столбчатой диаграммы.
Что видно из графиков: 1. Чем длиннее путь прокачки, тем выше винрейт. У путей 13+ винрейт стабильно выше 50%. 2. Высокий винрейт при KDA ~2-4 (дальнейший рост дает меньший эффект). 3. KDA растет с длинной пути. 4. Длинные и последовательные пути прокачки обеспечивают более высокий KDA и винрейт. 5. Эффективность сборки определяется глубинной прокачки, а не скоростью.
Визуализация успешных и неуспешных сборок героя Seven
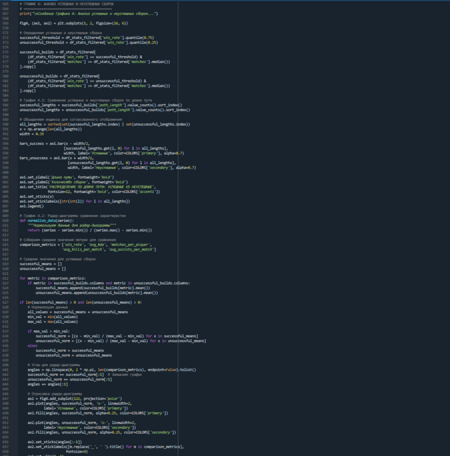
Четвертые графики — сравнительная визуализация успешных и неуспешных сборок героя Seven. Она позволяет исследовать структурные различия между этими двумя группами по нескольким ключевым параметрам и объясняет, какие характеристики отличают выигрышные стратегии от проигрышных.
Для этого применяются следующие статистические методы: — Квантильная сегментация — разделение всех сборок на группы с использованием 25-го и 75-го процентилей винрейт для определения «успешных» и «неуспешных» вариантов. — Сравнительный частотный анализ — сопоставление распределения длин путей между двумя группами через сгруппированные гистограммы. — Многомерное нормализованное сравнение — приведение разнородных метрик (винрейт, KDA, количество матчей и т. д.) к единой шкале для корректного сравнения на радар-диаграмме. — Полярная визуализация профилей — использование радар-диаграммы для одновременного отображения относительных значений пяти ключевых характеристик в каждой группе. — Контрастный анализ — прямое визуальное сопоставление двух групп по нескольким измерениям для выявления систематических различий.
Что видно из графиков: 1. Успешные сборки — это длинные пути прокачки (13+). 2. Короткие пути прокачки практически не приводят к успеху. 3. Успешные сборки превосходят неуспешные по KDA, ассистам и убийствам. Ключевой фактор для успешной сборки — это ассисты.
Вывод
Результаты этого исследования — это двойной инструмент. Непосредственно для игры они раскрывают мету и оптимальные стратегии для Seven, повышая мою эффективность. В более широком смысле — это отработанная методология анализа игрового баланса, которую я в будущем смогу масштабировать на других персонажей в MOBA-играх.
Инструменты и источники данных
Использованные ресурсы: 1. ChatGPT (OpenAI): https://chatgpt.com. Применялась для разработки и анализа на разных этапах работы.
Источник данных: 1. Deadlock API — официальное API для доступа к статистике матчей, данным игроков и сборкам героев. Доступ: https://api.deadlock-api.com/docs



