
Факторы учебной успеваемости: анализ поведенческих данных студентов
Концепция
Для анализа был выбран датасет Student Performance с Kaggle. Он содержит информацию о результатах студентов по разным предметам, а также дополнительные факторы, которые могут влиять на успеваемость, такие как количество сна, внеучебная активность, предыдущие оценки и часы обучения.

Тема интересна, так как позволяет выявить закономерности, влияющие на учебные результаты, и понять, какие факторы наиболее значимы для достижения высоких показателей и наконец понять сколько нужно спать и учиться, чтобы получать хорошие оценки.

Использовались scatter plot, bar chart, boxplot и линейные графики, чтобы показать связи между часами обучения, сном, внеучебной активностью и предыдущими результатами с текущей успеваемостью. Такой подход позволяет изучать данные и объяснять закономерности визуально.

Для визуализации данных я сознательно выбрал тёмную цветовую схему с преобладанием глубокого синего фона и светлых акцентных элементов. Такой стиль отсылает к интерфейсам аналитических инструментов, дашбордов и научных визуализаций, где ключевая задача — удержать внимание пользователя на данных, а не на декоративных элементах.
Обработка данных
В начале работы я подключаю все необходимые библиотеки, которые понадобятся для анализа и визуализации данных.
import pandas as pd import matplotlib.pyplot as plt import numpy as np from matplotlib import font_manager, rcParams
После подключения библиотек я задаю единый визуальный стиль для всех графиков. Это важный шаг, так как консистентный стиль повышает наглядность и эстетичность визуализации. Добавляю кастомные цвета и моноширинный шрифт.
rcParams['font.family'] = 'monospace' rcParams['axes.unicode_minus'] = False
BLUE_BG = '#133C55' WHITE = '#F5F7DC' ACCENT = '#59A5D8' ACCENT2 = '#91E5F6'
plt.rcParams.update ({ 'figure.facecolor': BLUE_BG, 'axes.facecolor': BLUE_BG, 'axes.edgecolor': WHITE, 'axes.labelcolor': WHITE, 'xtick.color': WHITE, 'ytick.color': WHITE, 'text.color': WHITE, 'axes.titlecolor': WHITE, 'grid.color': WHITE, 'font.size': 11 })
Далее я загружаю датасет с успеваемостью студентов с помощью pandas.read_csv (). После загрузки я сразу выполняю первичный осмотр данных и преобразую категориальный столбец «Extracurricular Activities» в числовой формат:
df = pd.read_csv («/content/StudentPerformance.csv») df.head ()
df.info ()
df.describe ()
df['Extracurricular Activities'] = df['Extracurricular Activities'].map ({ 'Yes': 1, 'No': 0 })
Визуализация данных
Сначала я строю scatter plot, отображающий зависимость между часами обучения и показателем успеваемости. Этот график позволяет визуально выявить тренды: например, как увеличение времени, затраченного на обучение, влияет на итоговые результаты.
plt.figure (figsize=(15,10)) plt.scatter (df['Hours Studied'], df['Performance Index'], alpha=0.3) plt.title ('Зависимость успеваемости от часов обучения') plt.xlabel ('Часы обучения') plt.ylabel ('Показатель эффективности') plt.show ()
Почему scatter: он идеально подходит для отображения числовых данных двух переменных, чтобы оценить взаимосвязь, выявить выбросы и закономерности.
Точечная диаграмма. Зависимость между часами обучения и показателем успеваемости.
Для оценки влияния сна на успеваемость я группирую студентов по количеству часов сна и вычисляем средний показатель эффективности в каждой группе, после чего строим столбчатую диаграмму.
sleep_perf = df.groupby ('Sleep Hours')['Performance Index'].mean () plt.figure (figsize=(15,10)) plt.bar (sleep_perf.index, sleep_perf.values) plt.title ('Средний результат в зависимости от количества сна') plt.xlabel ('Часы сна') plt.ylabel ('Средний Показатель эффективности') plt.show ()
Bar chart хорошо подходит для отображения агрегированных данных и позволяет быстро сравнить средние значения между категориями.
Столбчатая диаграмма. Зависимость от количества сна.
Для анализа структуры данных я использую круговую диаграмму, чтобы показать долю студентов, участвующих и не участвующих во внеучебной деятельности.
plt.figure (figsize=(15,10))
activity_counts = ( df['Extracurricular Activities'] .value_counts () .sort_index () )
plt.figure (figsize=(15,10))
plt.pie ( activity_counts.values, labels=['Нет', 'Да'], autopct='%1.1f%%', startangle=90, colors=[ACCENT2, ACCENT], textprops={'color': WHITE, 'fontsize': 11} )
Вместе с круговой диаграммой я строю boxplot, который показывает распределение показателей успеваемости в зависимости от участия во внеучебной активности.
plt.title ('Доля студентов, участвующих во внеучебной деятельности') plt.show ()
plt.figure (figsize=(15,4)) df.boxplot (column='Performance Index', by='Extracurricular Activities') plt.title ('Влияние внеучебной активности на успеваемость') plt.suptitle ('') plt.xticks ([1,2], ['Нет', 'Да']) plt.xlabel ('Внеклассные активности') plt.ylabel ('Показатель эффективности') plt.show ()
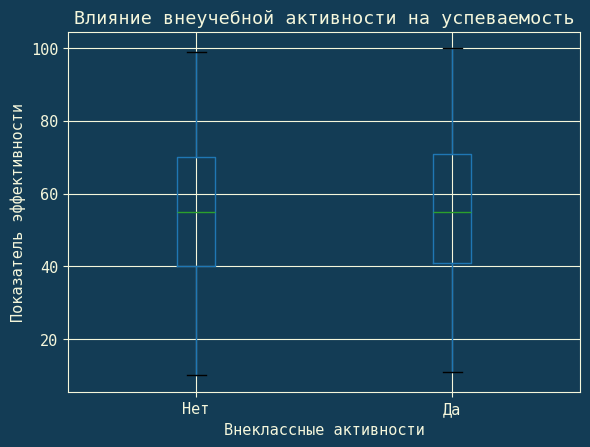

Диаграмма и Boxplot.Доля студентов, участвующих во внеучебной деятельности и влияние внеучебной активности на успеваемость.
Здесь я снова использую scatter plot, чтобы проанализировать связь между предыдущими результатами студентов и их итоговой успеваемостью.
Этот график позволяет оценить наличие корреляции и понять, насколько прошлые достижения влияют на текущие результаты.
plt.figure (figsize=(15,10)) plt.scatter (df['Previous Scores'], df['Performance Index'], alpha=0.3) plt.title ('Связь предыдущих результатов с итоговой успеваемостью') plt.xlabel ('Предыдущие результаты') plt.ylabel ('Показатель эффективности') plt.show ()
activity_stats = ( df .groupby ('Extracurricular Activities')['Performance Index'] .agg (['mean', 'std']) .reset_index () )
activity_counts = ( df['Extracurricular Activities'] .value_counts () .sort_index () )
Scatterplot.Связь предыдущих результатов с итоговой успеваемостью
Описание применения генеративной модели
Для своей работы я использовал Chat-GPT версии 5.0. Он помог мне кастомизировать цветовую палитру и подобрать нужный вариант шрифта.
Ссылка на модель: https://openai.com/ru-RU/gpt-5/
Список источников
https://www.kaggle.com/datasets/neurocipher/student-performance (датасет)
https://matplotlib.org/stable/api/matplotlib_configuration_api.html (документация по matplotlib)
https://thecode.media/biblioteka-matplotlib/?ysclid=mjd9aod2lr939878970 (статья по matplotlib)



