
Исходные данные: цель исследования
Цель данного проекта — найти и проанализировать табличные данные и сделать выводы об исследованном. Для анализа я использовала сайт kaggle.com и выбрала такую информацию как «Самая популярная манга». Я решила взять именно эту информацию, так как она близка по моему учебному профилю. Также я давно интересуюсь именно мангой, и мне было интересно увидеть динамику популярности книг, узнать о таковой у их авторов и издательств.
Графики и принцип их выборки
Для иллюстрации моих данных я использовала различные графики. Их многообразие можно объяснить не только эстетическим решением, но и их разными иллюстративными способностями. Так, например, круговая диаграмма нагляднее покажет процентное соотношение одного к другому, чем линейная.
Разработка: как я обрабатывала данные
Все графики следовали принципу «„Топ 30/5…“. И это неудивительно: по своей сути таблица уже была неупорядоченным топом нескольких позиций сразу. Я проиллюстрировала эти позиции при помощи разных типов графиков, так как они позволяют по-разному взглянуть на полученные данные и сделать свои выводы, о которых чуть позже. Подробнее о своих рассуждениях и решениях я расскажу в разделе „Итоговые графики“.
Стиль графиков
Своеобразной айдентикой выступил цвет графиков — розовый и его оттенки, так как именно он навевает ассоциации с Азией, что подходит тематически. Еще одним, пусть и незначительным решением, стало расположение текста для подписей под углом 90 градусов. Это своеобразный оммаж на те же азиатские языки, которые зачастую пишутся в манге/манхве сверху вниз.
Итоговые графики
Код: from google.colab import drive drive.mount ('/content/drive') import pandas as pd import matplotlib.pyplot as plt
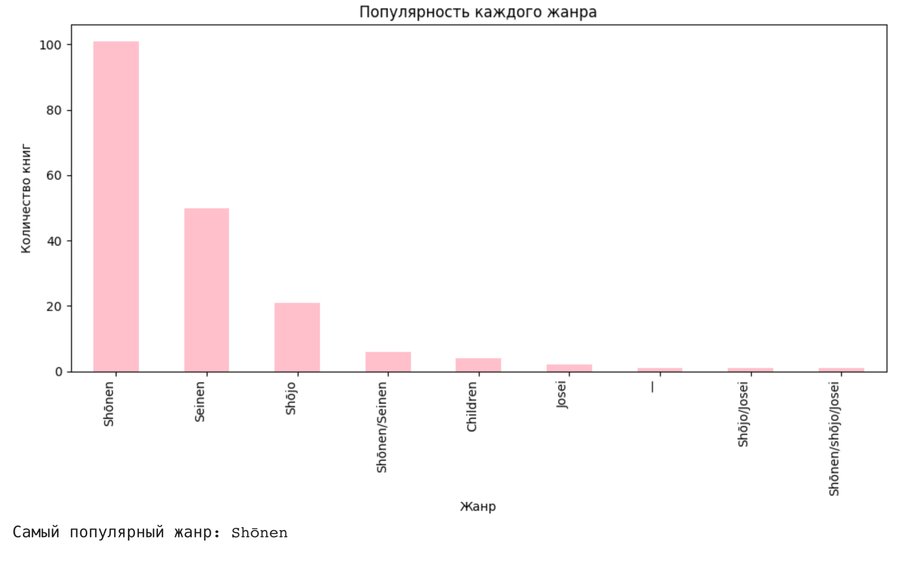
most_common_demographic = data['Demographic'].mode ()[0] genre_popularity = data['Demographic'].value_counts () genre_popularity = genre_popularity.sort_values (ascending=False) plt.figure (figsize=(10, 6)) genre_popularity.plot (kind='bar', color='pink') plt.title ('Популярность каждого жанра') plt.xlabel ('Жанр') plt.ylabel ('Количество книг') plt.xticks (rotation=90, ha='right') plt.tight_layout () plt.show () print (f"Самый популярный жанр: {most_common_demographic}»)
Первое, что я решила узнать — какой же жанр самый популярный. Для этого подошла столбчатая диаграмма, наглядно показывающая соотношение каждого столбца с предыдущим и последующим.
Код: from google.colab import drive drive.mount ('/content/drive') import pandas as pd import matplotlib.pyplot as plt
author_counts = data['Author (s)'].value_counts () top_5_authors = author_counts.head (30) plt.figure (figsize=(10, 6)) plt.plot (top_5_authors.index, top_5_authors.values, marker='o', linestyle='-', color='pink') plt.xlabel ('Имя авторов') plt.ylabel ('Частота упоминаний') plt.title ('Топ 30 авторов') plt.xticks (rotation=90) plt.tight_layout () plt.show ()
Для выявления популярности конкретного автора я использовала линейную диаграмму. Пришлось взять первые 30 авторов (с помощью функции .head), так как график получался большим и не информативным. С дальнейшими графиками я также использовала head если полномасштабный график не нес большой информационной нагрузки.
Код: from google.colab import drive drive.mount ('/content/drive') import pandas as pd import matplotlib.pyplot as plt
author_counts = data['Author (s)'].value_counts () top_10_authors = author_counts.head (10) pink_colors = ['#FFC0CB', '#FF69B4', '#FF1493', '#DB7093', '#C71585', '#FF0090', '#FF007F', '#FF3E96', '#FF34B3', '#FF82AB'] plt.figure (figsize=(8, 8)) plt.pie (top_10_authors.values, labels=top_10_authors.index, autopct='%1.1f%%', startangle=140, colors=pink_colors) plt.title ('Топ 10 самых популярных авторов') plt.tight_layout () plt.show ()
Круговая диаграмма была использована для наглядности: при помощи нее можно увидеть, каково настоящее соотношение «сторон» в лице популярности каждого автора. Эту самую популярность я получила, ссылаясь на количество упоминаний таковых в таблице. Здесь я выбрала уже не 30, а 10 авторов, так как иначе названия накладывались друг на друга, и в целом такая круговая диаграмма не была бы достаточно наглядной. Как можно заметить, здесь я уже указывала цвет не как pink, а как цветовые коды. Таким образом диаграмма выглядит более интересной и понятной, в то же время не отступая от установленной айдентики
Код: from google.colab import drive drive.mount ('/content/drive') import pandas as pd import matplotlib.pyplot as plt
sorted_data = data.sort_values (by='Serialized') plt.figure (figsize=(10, 6)) top_30_earliest = sorted_data.head (30) sizes = [200 — (i * 5) for i in range (len (top_30_earliest))] plt.figure (figsize=(12, 8)) plt.scatter (top_30_earliest['Serialized'], top_30_earliest['Manga series'], color='#FFC0CB', s=sizes) plt.xlabel ('Дата выпуска', fontsize=12) plt.ylabel ('Название', fontsize=12) plt.title ('Топ 30 самых ранних книг по дате выпуска (размер точек зависит от давности)', fontsize=14) plt.grid (True, linestyle='--', alpha=0.6) plt.xticks (rotation=90) plt.tight_layout () plt.show ()
На данный график стоит смотреть не с точки зрения «выше — лучше», а обращая внимание на размер точек. Точечная диаграмма выполнена при помощи функции .scatter. Таким образом мы видим, что самой ранней мангой в таблице является Сазае-Сан
Код: from google.colab import drive drive.mount ('/content/drive') import pandas as pd import matplotlib.pyplot as plt
file_path = '/content/drive/My Drive/best-selling-manga 2.csv' data = pd.read_csv (file_path) publisher_popularity = data.groupby ('Publisher')['Approximate sales in million (s)'].sum ().reset_index () top_20_publishers = publisher_popularity.sort_values (by='Approximate sales in million (s)', ascending=False).head (20) plt.figure (figsize=(10, 10)) plt.bar (top_20_publishers['Publisher'], top_20_publishers['Approximate sales in million (s)'], color='pink') plt.xlabel ('Издательство') plt.ylabel ('Популярность') plt.title ('Топ 20 самых популярных издательств') plt.xticks (rotation=90) plt.tight_layout () plt.show ()
В этом графике говорится уже о популярности издательств. Здесь могла бы подойти и круговая диаграмма, но я решила прибегнуть к коду, использованному ранее, и создать столбчатую. Столбчатая диаграмма отвечает на вопрос «кто лучше?», не вдаваясь в детали по типу процентов. Именно это мне было нужно.
Описание применения генеративной модели
Для иллюстративной (обложка этого проекта) и генеративной части я прибегала к использованию нейросетей Ideogram.ai и DeepSeek. Вторая помогала в случаях, когда моих знаний было недостаточно для нужного отображения, я не знала, как оформить мысль в код или не понимала, где и какую ошибку допустила. Также нейросеть — хороший помощник в определении рандомного набора чего-либо (в моем случае оттенков цветов)
Генерация нейросетью рандомного набора розовых оттенков для круговой диаграммы. Позже палитра была расширена, так как 10 позиций смотрелось нагляднее, чем 5.
Нейросеть помогает искать ошибки в коде. В данном случае я забыла, что название колонки «Demographic» написано с маленькой буквы, из-за чего питон не понимал, о чем идет речь.
Промпт: a samurai from junji ito manga surfing through countless python data and histograms with pie charts. The picture is black and pink, with intricate details in the background.


